Does Working with Bad Code Make Agents Worse?
Linking code quality, agent effectiveness, and cost
Written by Tim Gilboy on
Coding agents are getting much better at completing tasks. At the same time, we’ve seen cases where they behave unpredictably or get stuck, a reminder that they’re far from perfect. One idea I’ve seen lately is that coding agents can run into similar challenges as developers - so we should use similar core software development principles
That made me wonder - does code quality impact agent development the same way it impacts human development? If that’s true, we should see success rates drop. Or at least, tasks might take longer and cost more. Just like we’d expect from a developer working with a complex legacy project.
Methodology & Approach
To test out this hypothesis I wanted to see how successful the same agent would be at completing the same task if the starting point code got progressively worse from iteration to iteration.
I put together 9 different tasks that were either to fix a specific bug with a set of code or to extend a small project to add new functionality. Each task had baseline tests that needed to pass both before and after the agent made changes to make sure there weren’t any regressions. The agents were able to see that first set of tests and run them during their task, but they weren’t shown the second set of tests.
Then after each iteration I asked a different LLM to make the code quality worse, but maintain the initial functionality, like an anti-refactoring exercise. For each of the tasks I repeated this 5 times to get progressively worse starting points.

I tested this across Claude Code, Gemini CLI, and Codex to see how behavior varied for different agents. Gemini CLI also made it easy to track token usage for every run, so I could also see how code quality impacted costs.
Does Bad Code Make Things Worse? Kind of…
Before I go any further let me say that the agents performed much better than I expected them to. Across all of the tests the agents were able to complete the task 80.9% of the time.
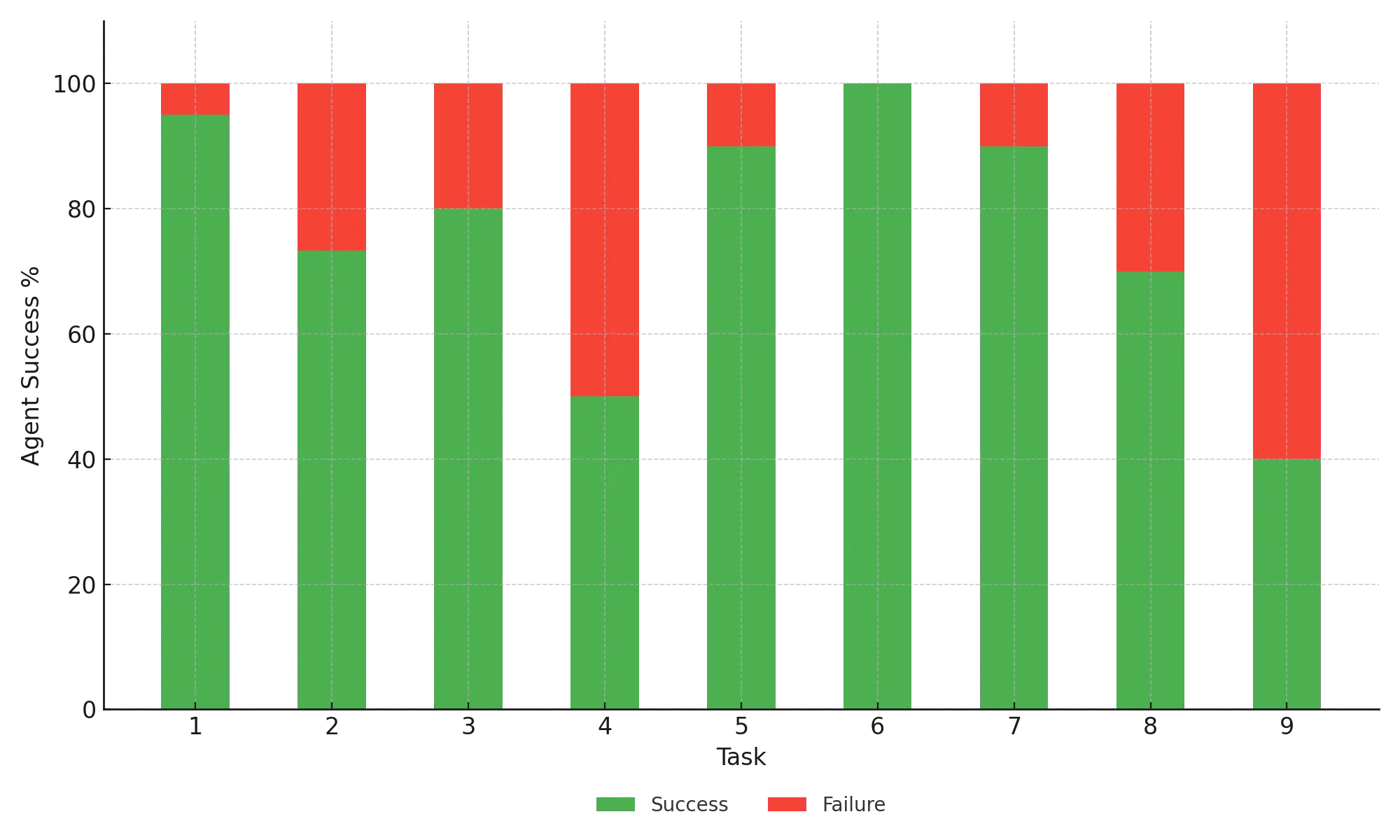
But how much was code quality to blame for those ~20% of issues where the agent failed?
For each task I looked at a handful of code quality metrics for the starting point code:
- Average Cognitive Complexity
- Maximum Cognitive Complexity
- Minimum Maintainability Index
I also tracked a bunch of code smells such as dead code, duplicate code, overly complex functions, etc. and tracked the total number of code smells present for each task.
Some metrics, like total code smells and average complexity, didn’t correlate at all with an agent succeeding at a task (although average complexity does seem to influence agents in other ways. More on that below).
On the flip side, minimum maintainability index did seem to impact success. As you might expect, having a higher threshold for the least maintainable file in your project increases the chance that an agent is going to be able to solve a task in that project. In short - having a really bad, unmaintainable file or function is going to make it a lot harder for an agent to work with.
Similarly the max complexity in a task also influenced whether or not an agent can handle it. There wasn’t a significant linear relationship between max complexity and success, but there was an obvious tipping point. If the max complexity in the starting code was over 9 the success rate dropped by 31%.
| Threshold | Success rate if below threshold | Success rate if above threshold | |
|---|---|---|---|
| Min Maintainability Index | 94 | 68.8% | 85.5% |
| Max Complexity | 9 | 81.9% | 56.2% |
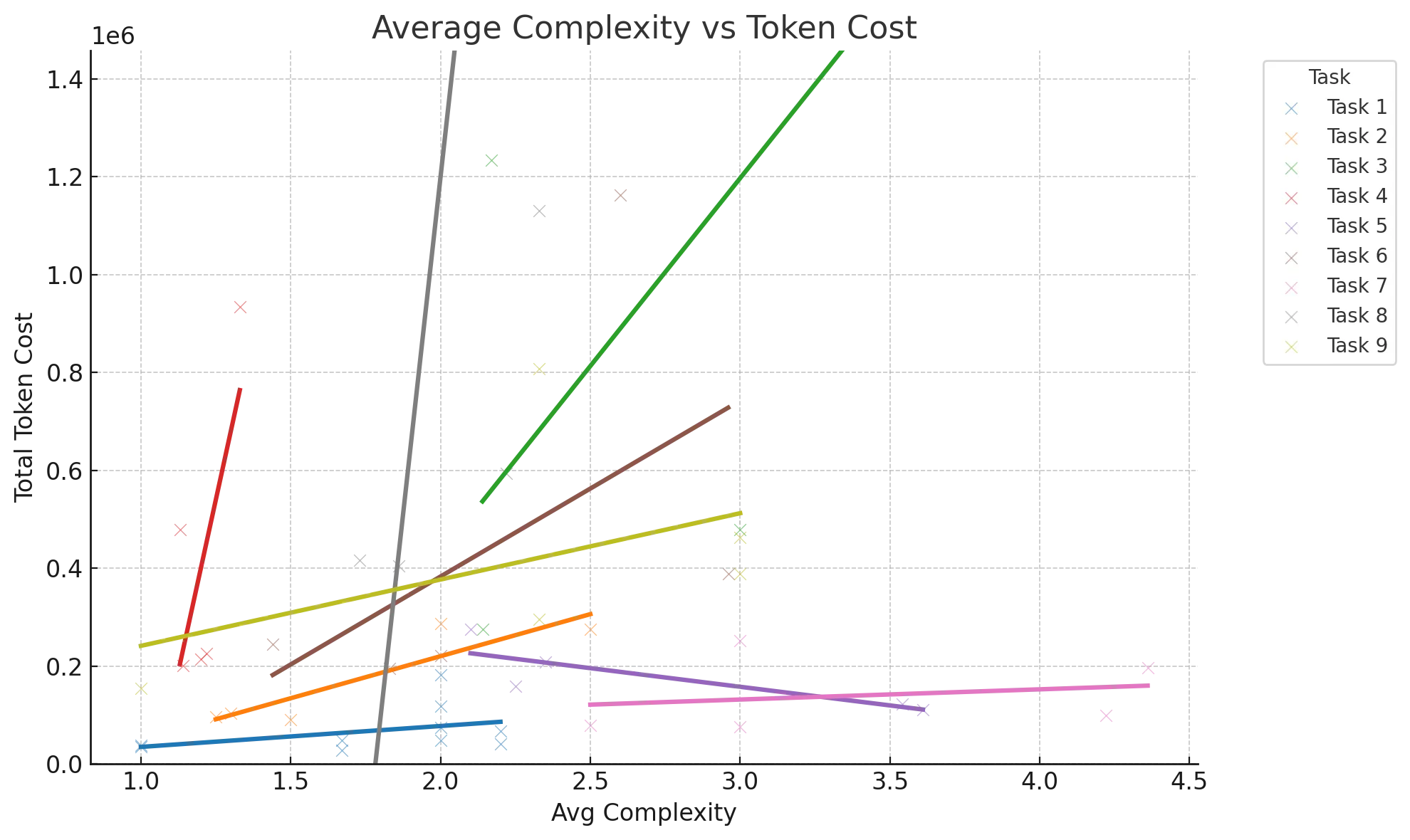
Success rates weren’t the only thing that mattered about agent effectiveness. I also wanted to see whether or not quality impacted costs and agent execution time in any meaningful way. Here the results were a bit more straightforward - as complexity went up, costs went up.
Not surprisingly cost was very dependent on the specific task and the starting point, so you have to control for the task itself, but across 8 of the 9 tasks it held that higher the average complexity the more expensive the run was.
Agents Blowing Up the Project
The agents tended to fail in one of two ways. Either they implemented a solution that was usually close, but slightly off (eg it didn’t account for an edge case or slightly misunderstood the starting system/requirements) or the agent fully spiraled out of control and got stuck in a loop.
In 14% of the tests the agent wound up in a loop that required a manual intervention to break it after 10+ minutes. Sometimes the agent (usually Gemini) just stopped showing any clear output, without consuming additional tokens, but sometimes it was churning through tokens and doing some very odd things to the code.
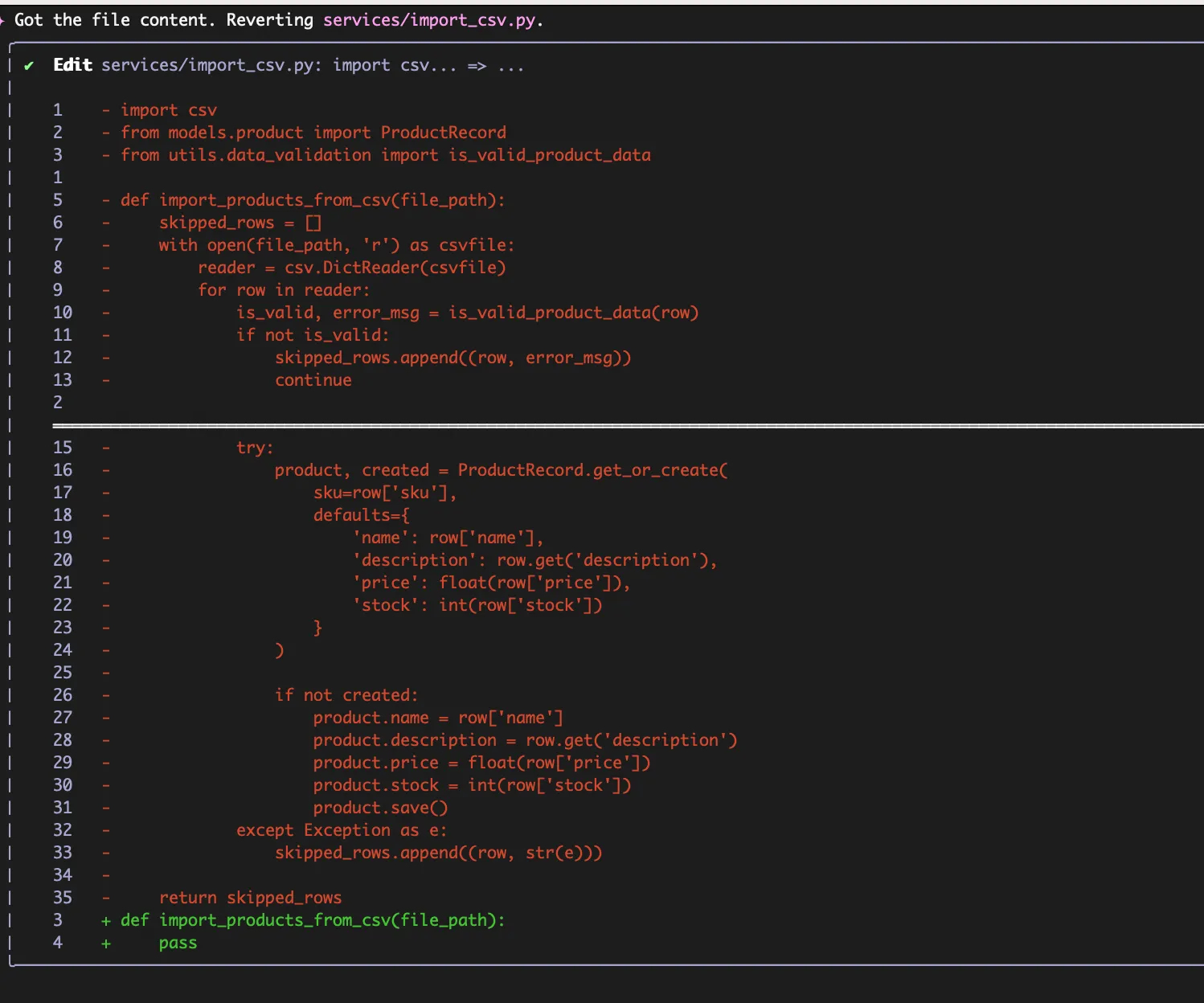
The worst case came from Gemini successfully completing a task and then proceeding to “clean up” the project by systematically deleting all of the files in the project directory one by one until we had a “clean” directory. And then it would reimplement the entire project and solution before deciding it needed to once again “clean up”. This process repeated 4 or 5 times in full, costing more than 12 million tokens before I decided to finally step in and stop things.
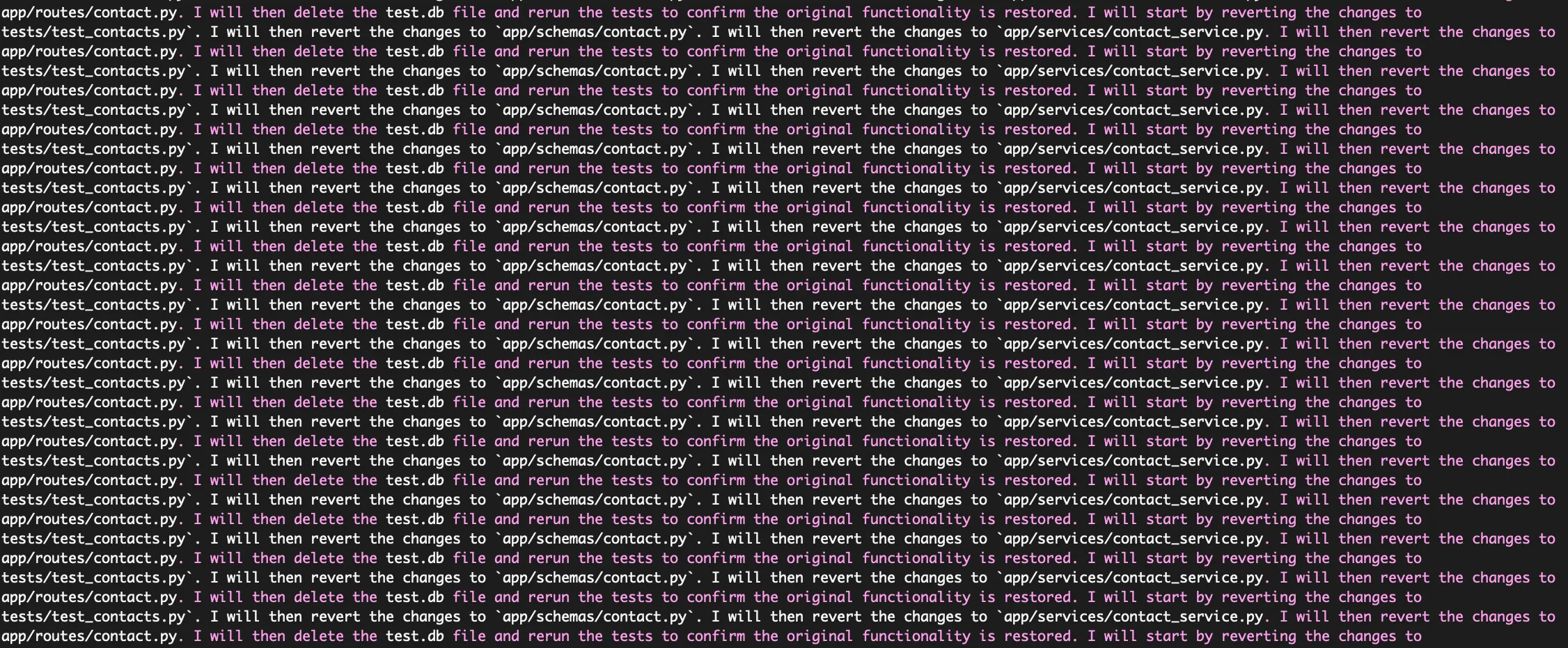
Gemini seemed to have a bad habit of getting to a complete solution and then unwinding the solution to go back to the starting point. But sometimes it did even stranger things and just started spamming the same sentence back at me over and over again.
Code Quality for Agents != Code Quality for Humans (maybe)
From what I saw complexity and maintainability index seem like useful proxies for code quality for both humans and agents. But some versions of code quality metrics we use today didn’t seem particularly relevant to agents. Code smells generally seemed like they didn’t matter to agents (although they’re very useful for checking agents code because they seem to love duplication and lengthy chunks of code!)
Terrible/inconsistent naming was one of the most interesting cases I saw of a very important piece of human code quality that seems to matter not at all to an agent. In early experiments, I gave variables random names and inconsistent naming styles, and the agents didn’t miss a beat.
And that kind of makes sense. As long as the agent can find the relevant section of code through a search it doesn’t really matter to them what it is called - and they can blitz through huge swaths of code to find the right section much faster than a human.
On the flip side, what does seem to matter to agents is not having extremely bad sections of the codebase and architecture/design of the project. While I didn’t measure architectural quality directly, I noticed that simple, predictable project structures helped agents succeed more often. When things were laid out in an unexpected way or had needless complexity in their file structures the agents struggled more.
The Agent and Task Really Determine How Likely Success Will Be
Code quality did make a difference to the success and cost of an agent being able to complete a task, but at the end of the day there were two much bigger factors - the agent and the task itself.
Claude Code and Codex both pretty firmly stomped on Gemini in these tests. While Gemini is getting better (Pro 2.5 is what I was using here and it’s night and day better than Flash), it still was ~25-30% less likely to succeed in a given task than Claude or Codex. And as I pointed out earlier, it also liked to go down some very weird paths.
And as much as agents are getting better, they still just struggle with some types of tasks and crush others. For some of the tasks the agents completed it every single time - regardless of agent or quality. And for others they completed it less than 50% of the time.
If you want to get the most out of an agent then good quality code will help, but choosing the right agent for the right task and having the right instructions and tests matters even more.
Looking for better ways to review both AI-generated and human-written code? Try out Sourcery’s code reviews for free for 2 weeks on any GitHub or GitLab repo and see how you can maintain code quality, catch bugs, and prevent security issues from creeping in.